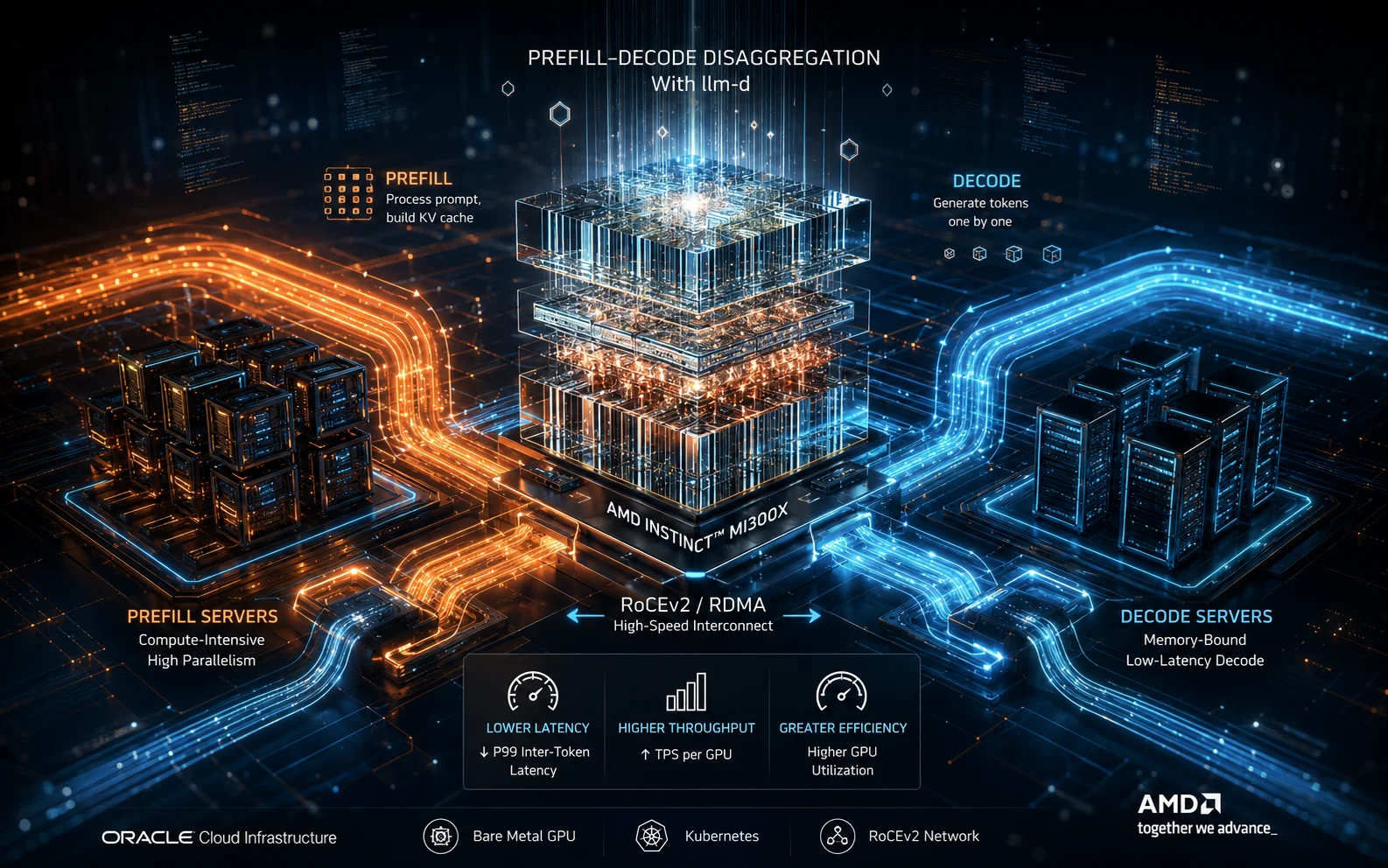
Εισαγωγή: Βελτιστοποίηση της Εξυπηρέτησης Παραγωγής LLM με Διαχωρισμό Προκαταβολής-Αποκωδικοποίησης
Η εξυπηρέτηση παραγωγής των μεγάλων γλωσσικών μοντέλων (LLM) αποτελεί τελικά ένα πρόβλημα βελτιστοποίησης των στόχων επιπέδου υπηρεσίας (SLO). Οι ομάδες δεν επιδιώκουν απλώς να μεγιστοποιήσουν την ακατέργαστη απόδοση, αλλά να επιτύχουν τους σωστούς στόχους καθυστέρησης και απόκρισης με το χαμηλότερο δυνατό κόστος υποδομής. Η διαχωρισμένη εξυπηρέτηση προκαταβολής-αποκωδικοποίησης με το llm-d1 προσφέρει έναν ισχυρό τρόπο για να επιτευχθεί αυτό, αλλά η αξιοποίηση των πλεονεκτημάτων της απαιτεί μια πειθαρχημένη προσέγγιση για την αναγνώριση της σωστής διαμόρφωσης για ένα συγκεκριμένο μοντέλο, φόρτο εργασίας και στόχο υπηρεσίας. Σε αυτό το άρθρο, παρουσιάζεται μια πρακτική μεθοδολογία για τη ρύθμιση της διαχωρισμένης εξυπηρέτησης PD, ώστε να επιτευχθούν οι στόχοι SLO με αποδοτικό τρόπο σε GPU AMD Instinct™ MI300X που φιλοξενούνται σε bare-metal GPU της OCI με δίκτυο RDMA πίσω από το RoCEv2.
Ξεκινάμε με την ανεξάρτητη αξιολόγηση των κύριων φάσεων της παραγωγής: αποκωδικοποίηση, προκαταβολή και συνολική εξυπηρέτηση. Με την απομόνωση αυτών των συμπεριφορών, οι επαγγελματίες μπορούν να κατανοήσουν καλύτερα το φάσμα απόδοσης κάθε σταδίου και να εντοπίσουν διαμορφώσεις υποψηφίων που ταιριάζουν καλά στο προφίλ υπολογισμού του μοντέλου. Αντί να μαντεύουν το σχήμα του συμπλέγματος ή τις αναλογίες πόρων, αυτό παρέχει ένα θεμελιωμένο σημείο εκκίνησης για την επιλογή διαμόρφωσης.
Ανάλυση και Αξιολόγηση των Υποψηφίων Διαμορφώσεων
Από εκεί, πραγματοποιούμε μια ανάλυση Pareto σε υποψήφιες διαμορφώσεις για να αξιολογήσουμε τις ανταλλαγές μεταξύ καθυστέρησης, ταυτόχρονης εκτέλεσης και αποδοτικότητας. Αυτό καθιστά δυνατή την αναγνώριση των βέλτιστων διαμορφώσεων σε διαφορετικά επίπεδα φόρτου και πού τα οφέλη του διαχωρισμού γίνονται πιο εμφανή. Αντί για μια μοναδική “καλύτερη” διαμόρφωση, το αποτέλεσμα είναι ένα πλαίσιο απόφασης: ποια διαμόρφωση PD έχει νόημα για έναν δεδομένο στόχο ταυτόχρονης εκτέλεσης και απαίτηση SLO.
Τέλος, επικυρώνουμε την επιλεγμένη διαμόρφωση με μια εκτέλεση κλίμακας, δείχνοντας πώς η μεθοδολογία επεκτείνεται από την αξιολόγηση ενός σταδίου σε μια ρεαλιστική κατανεμημένη ανάπτυξη. Το αποτέλεσμα είναι μια επαναλαμβανόμενη διαδικασία για τη μετάβαση από δεδομένα μικροαξιολόγησης σε αρχιτεκτονική εξυπηρέτησης έτοιμη για παραγωγή, βοηθώντας τελικά τις ομάδες να χρησιμοποιήσουν το llm-d για να επιτύχουν τους στόχους SLO με την πιο αποδοτική διαμόρφωση προκαταβολής-αποκωδικοποίησης.
Πώς να Διαμορφώσετε τον Διαχωρισμό Προκαταβολής-Αποκωδικοποίησης
Ο κύριος λόγος για τη χρήση του διαχωρισμού προκαταβολής-αποκωδικοποίησης είναι ότι επιτρέπει την εξειδίκευση μεταξύ των φάσεων προκαταβολής και αποκωδικοποίησης της πρόβλεψης. Η προκαταβολή είναι υπολογιστικά βαριά, και ένα μόνο αίτημα μπορεί να αξιοποιήσει πλήρως την υπολογιστική ισχύ της GPU. Αντίθετα, η αποκωδικοποίηση απαιτεί μεγάλη κίνηση δεδομένων και χρειάζεται μεγάλο αριθμό ταυτόχρονων αιτημάτων για να κορεστεί η υπολογιστική ισχύς στα γραμμικά στρώματα ενός LLM, απαιτώντας έτσι μεγάλο χώρο για την κρυφή μνήμη KV. Με τον διαχωρισμό P/D, μπορούμε να παραλληλίσουμε τις φάσεις προκαταβολής και αποκωδικοποίησης διαφορετικά.
Αξιολόγηση των Ανταλλαγών Απόδοσης
Για να αξιολογήσουμε τις ανταλλαγές απόδοσης μεταξύ συγκεντρωτικών και διαχωρισμένων διαμορφώσεων, σχεδιάζουμε την Απόδοση ανά GPU (TPSG) έναντι της Απόδοσης ανά Χρήστη (TPSU). Το TPSU, μετρημένο σε tokens ανά δευτερόλεπτο ανά χρήστη, αντιπροσωπεύει την αλληλεπίδραση του συστήματος. Το TPSG, μετρημένο σε tokens ανά δευτερόλεπτο ανά GPU, καταγράφει την αποδοτικότητα της υποδομής. Όσο υψηλότερο είναι το TPSG σε κάποιο TPSU, τόσο καλύτερα.
Συμπεράσματα και Εφαρμογές
Αυτή η εργασία δείχνει ότι η διαχωρισμένη εξυπηρέτηση προκαταβολής-αποκωδικοποίησης με το llm-d παρέχει μια συστηματική πορεία για τη βελτιστοποίηση των SLO πρόβλεψης στην υποδομή AMD MI300X. Η ανάλυση Pareto δείχνει ότι στο μεσαίο εύρος αλληλεπίδρασης, οι διαχωρισμένες αρχιτεκτονικές έχουν σταθερά υψηλότερη αποδοτικότητα GPU σε σύγκριση με τις συγκεντρωτικές διαμορφώσεις, μεταφραζόμενη άμεσα σε μειωμένα λειτουργικά κόστη για την εξυπηρέτηση LLM σε επιχειρήσεις. Επιπλέον, το πείραμα κλιμάκωσης επιβεβαιώνει ότι αυτά τα οφέλη επεκτείνονται σε αναπτύξεις πολλαπλών κόμβων, όπου μια διαχωρισμένη διάταξη με λιγότερους κόμβους μπορεί να υπερέχει των συγκεντρωτικών διαμορφώσεων σε υψηλότερους ρυθμούς αιτήσεων, ενώ διατηρεί χαμηλότερη καθυστέρηση P99 μεταξύ των tokens.














{kind=link}