
Ένας ανοιχτός «research agent» 7 δισ. παραμέτρων
Η ανάπτυξη μοντέλων μεγάλου μεγέθους (LLMs) που μπορούν να λειτουργούν ως «ερευνητικοί πράκτορες»—δηλαδή να διατυπώνουν πολύπλοκες ερωτήσεις, να αναζητούν πληροφορίες εξωτερικά, να αξιολογούν, να συνδυάζουν και να συνθέτουν απαντήσεις—βρίσκεται σε ενεργή εξέλιξη. Το PokeeResearch-7B αποτελεί ένα τέτοιο βήμα: ένα μοντέλο 7 δισ. παραμέτρων που αποκαλείται “deep research agent” και έχει ανοικτό κώδικα / βάρη.
Σε αυτό το άρθρο, αναλύουμε τις βασικές αρχές λειτουργίας του, τη μεθοδολογία εκπαίδευσης, το reasoning scaffold, τα αποτελέσματα και τη σημασία του για χρήση σε ερευνητικά και επαγγελματικά περιβάλλοντα.
Τι είναι το PokeeResearch-7B
Το PokeeResearch-7B αναπτύχθηκε από την Pokee AI ως ένα μοντέλο που όχι μόνο παράγει κειμενικές απαντήσεις, αλλά υλοποιεί έναν πλήρη “loop” έρευνας-αξιολόγησης με εξωτερικά εργαλεία.
Πιο συγκεκριμένα:
- Διασπά το ερώτημα σε υποερωτήματα (decomposition).
- Εκτελεί κλήσεις εργαλείων (web search, ανάγνωση σελίδων) για συλλογή δεδομένων.
- Εξετάζει (self-verification) τις απαντήσεις με βάση τα ερευνητικά στοιχεία.
- Συνθέτει πολλαπλά ερευνητικά νήματα (research threads) σε τελική απάντηση.
Χαρακτηριστικά: Finetuned πάνω στη βάση της Qwen2.5‑7B‑Instruct.
Έτσι, απευθύνεται σε χρήστες που απαιτούν έρευνα με υψηλότερη αξιοπιστία, τεκμηρίωση και χρήση εργαλείων — όχι απλά «μεγάλο γλωσσικό» μοντέλο.

Μεθοδολογία Εκπαίδευσης – RLAIF & RLOO
Ένα από τα πιο ενδιαφέροντα χαρακτηριστικά είναι η εκπαιδευτική προσέγγιση:
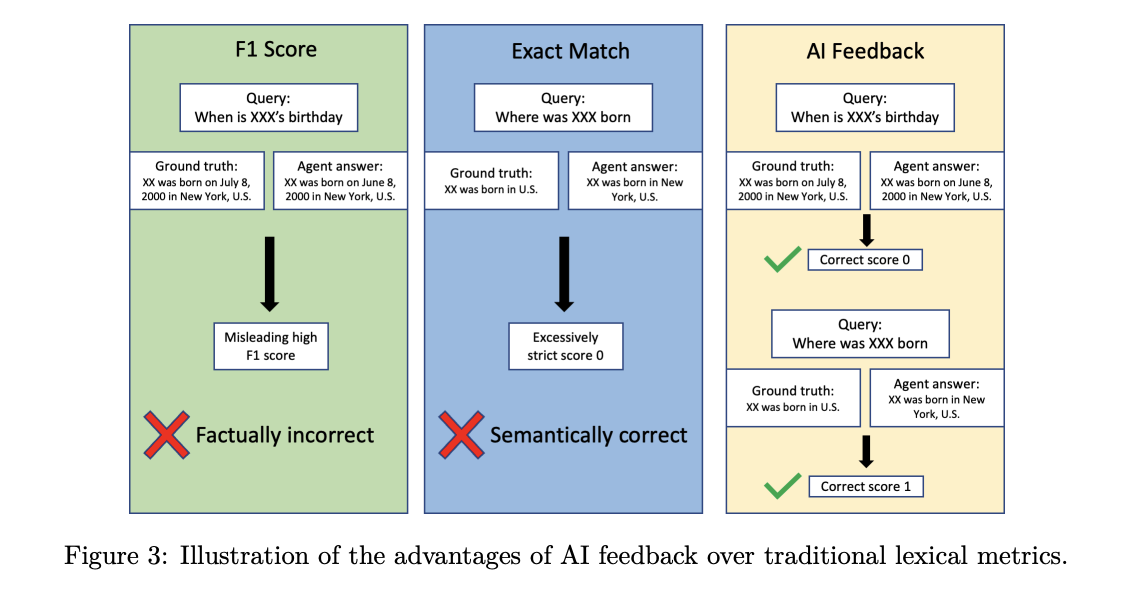
RLAIF (Reinforcement Learning from AI Feedback)
Η εκπαίδευση γίνεται με αξιολογήσεις από άλλο LLM (AI feedback) και όχι απλώς με supervision μετα-ετικετών.
RLOO (REINFORCE Leave-One-Out)
Χρησιμοποιείται ο αλγόριθμος RLOO για policy-gradient, ο οποίος η ομάδα επισημαίνει ότι είναι «αμερόληπτος on-policy» σε αντίθεση με το ευρύτερα χρησιμοποιούμενο Proximal Policy Optimization (PPO) που θεωρείται «περίπου on-policy και μεροληπτικός».
Παράμετροι εκπαίδευσης
- Batch size: 64
- Ερευνητικά νήματα (research threads) ανά prompt: 8
- Learning rate: 3 × 10⁻⁶
- Context length: 32 768 tokens
- Precision: bf16
- Checkpoint μέγεθος περίπου 13 GB
Η επιλογή των reward signals περιλαμβάνει:
- Σωστή σημασιολογικά απάντηση (semantic correctness)
- Πιστότητα στις παραπομπές / αποδείξεις (citation faithfulness)
- Συμμόρφωση με τις οδηγίες (instruction adherence)
και όχι απλώς overlap tokens με target (token overlap).
Η χρήση εξωτερικών δικτύων αξιολόγησης και ενσωμάτωσης εργαλείων καθιστά το μοντέλο πιο ευέλικτο και στοχαστικό.
Reasoning Scaffold & Συνθετική Έρευνα
Το μοντέλο δεν απλώς απαντά, αλλά υλοποιεί ένα “scaffold” που ενισχύει την αξιοπιστία· περιλαμβάνοντας:
- Self-correction: Αν διαπιστωθούν λανθασμένες κλήσεις εργαλείων (tool calls), το σύστημα κάνει retry.
- Self-verification: Επιθεωρεί την απάντησή του συγκρίνοντας με τα στοιχεία που έφερε.
- Research Threads Synthesis (RTS): Σε ένα ερώτημα τρέχουν πολλοί ανεξάρτητοι «νήματα» έρευνας· στο τέλος, τα αποτελέσματα συνοψίζονται και συγχωνεύονται σε τελική απάντηση.
Αυτή η δομή μειώνει την «εύθραυστη» συμπεριφορά (brittle trajectories) των μοντέλων που απλώς «μάντεψαν» με βάση το training set, καθώς αντιμετωπίζει εργαλειακή αποτυχία και εξασφαλίζει ευθυγράμμιση με αποδείξεις.
Για παράδειγμα, η επιλογή να τρέχουν 4 ή 8 threads ανά ερώτημα και να γίνεται mean@4 στην αξιολόγηση. Αυτό ανοίγει τον δρόμο για μεγαλύτερη ακρίβεια, ειδικά σε δύσκολα multi-hop ερωτήματα.
Πρωτόκολλο Αξιολόγησης
Η ομάδα της Pokee AI υιοθέτησε ένα αυστηρό πρωτόκολλο:
- Δέκα benchmark σύνολα ερωτήσεων: Natural Questions (NQ), TriviaQA, PopQA, HotpotQA, 2WikiMultiHopQA, Musique, Bamboogle, GAIA, BrowseComp, και Humanity’s Last Exam.
- Για κάθε σύνολο: δείγμα ~125 ερωτήσεων (εκτός GAIA με 103).
- Για κάθε ερώτημα: τρέχουν 4 ερευνητικά νήματα (threads) και υπολογίζεται mean@4 ακρίβεια.
- Μέγιστος αριθμός διαλόγων σε κάθε ερώτημα: 100 turn.
- Η αξιολόγηση της ορθότητας βασίζεται στο Gemini‑2.5‑Flash‑lite ως κριτή.
Αυτό το πρωτόκολλο δείχνει ότι η αξιολόγηση δεν είναι επιφανειακή αλλά δομημένη και απαιτητική.
Αποτελέσματα
Τα αποτελέσματα που αναφέρονται είναι εντυπωσιακά για το εύρος 7B παραμέτρων:
- Στο HLE (Humanity’s Last Exam): 15.2 % χωρίς RTS, 17.6 % με RTS.
- Στο GAIA: 36.9 % χωρίς RTS, 41.3 % με RTS.
- Στο BrowseComp: 5.4 % χωρίς RTS, 8.4 % με RTS.
- Σε άλλα QA σύνολα (Bamboogle, 2WikiMultiHopQA, TriviaQA, NQ, PopQA, Musique, HotpotQA) το μοντέλο «βελτιώνει σε σχέση με πρόσφατες 7B βάσεις».
Συμπέρασμα: Η προσθήκη του Research Threads Synthesis (RTS) έχει σημαντικό όφελος, κυρίως στα πιο απαιτητικά datasets (π.χ. HLE, GAIA). Το μοντέλο θέτει νέο «state-of-the-art» για έρευνα 7B παραμέτρων ανοιχτού κώδικα.
Πρακτικές Εφαρμογές & Προτάσεις Χρήσης
Πιθανοί τομείς χρήσης
- Ερευνητικά εγχειρήματα που απαιτούν συλλογή στοιχείων από το διαδίκτυο και σύνθεση.
- Ενσωμάτωση σε συστήματα «agent» που κάνουν autonomously έρευνα, π.χ. εταιρικές αναλύσεις, επιστημονικές εργασίες, αναφορές πολιτικής.
- «Backend» σε εργαλεία που απαιτούν τεκμηριωμένες απαντήσεις με παραπομπές και αναφορές.
Τι να έχετε υπόψη
- Αν και το μοντέλο στοχεύει σε υψηλή πιστότητα, έχει περιορισμούς: εξαρτάται από την ποιότητα των εργαλείων αναζήτησης/ανάγνωσης, υπάρχει κίνδυνος απόκλισης όταν οι πηγές δεν επαρκούν ή βρίσκονται σε σύγκρουση.
- Δεν προτείνεται για κρίσιμες αποφάσεις (ιατρικές, νομικές, χρηματοοικονομικές) χωρίς ανθρώπινο έλεγχο.
- Για ελληνικό ή ειδικό domain περιεχόμενο, μπορεί να απαιτείται επιπλέον fine-tuning ή προσαρμογή.
Προτάσεις ενσωμάτωσης
- Χρησιμοποιήστε το μοντέλο ως κομμάτι pipeline: σύστημα διερεύνησης → validaton → τελική σύνθεση.
- Ενσωματώστε εργαλεία monitoring της ποιότητας των αναφορών (citations) και αναδρομικής αξιολόγησης.
- Εκμεταλλευτείτε την ανοικτή διάθεση του μοντέλου (Apache-2.0) για customization ή fine-tuning σε domain-specific δεδομένα.
Σημασία & Συμπέρασμα
Το PokeeResearch-7B συμβολίζει μια μετατόπιση: από LLM που «απαντάνε» σε LLM που «ερευνούν». Η χρήση RLAIF και RLOO, μαζί με τον σχεδιασμό του reasoning scaffold, τον καθιστούν ένα πιο στιβαρό εργαλείο για πολύπλοκα ερευνητικά workflows.
Για έναν προγραμματιστή/τεχνικό όπως εσείς (με ενδιαφέρον για backend/AI) μπορεί να αποτελέσει βάση για ανάπτυξη agent-based συστημάτων που κάνουν έρευνα, αναλύουν αποτελέσματα, παράγουν συνθετικά πορίσματα — σε συνδυασμό με τα εργαλεία που ήδη εξετάζετε (VMs, backend infra, API integration).
Υπό αυτή την έννοια, πρόκειται για πολύ ενδιαφέρον ανοικτό έργο που αξίζει να εξεταστεί περαιτέρω.
Πηγή
- Yi Wan et al., “PokeeResearch: Effective Deep Research via Reinforcement Learning from AI Feedback and Robust Reasoning Scaffold”, arXiv, October 2025. (arXiv)















{kind=link}